 Em live, Diretor do DI apresentou kit de sensores e mobile hub para monitoramento de pacientes
Em live, Diretor do DI apresentou kit de sensores e mobile hub para monitoramento de pacientes
A Internet das Coisas tem múltiplas aplicações e uma delas pode ser a serviço da saúde. Pesquisador de IoMT (Internet of Mobile Things) Markus Endler, diretor do Departamento de Informática (DI) da PUC-Rio, mostrou na live do DI, na sexta-feira (16), projetos de software e hardware que podem ajudar no combate à Covid-19 monitorando os sinais vitais dos pacientes. “Cada vez mais temos dispositivos wearable (usáveis) muito bons, muito precisos, onde se pode medir, por exemplo, a insulina, o pulso, o oxímetro… o que é muito importante na pandemia”, disse.
No seminário “Middleware para Internet das Coisas com Mobilidade”, transmitido pelo YouTube e pelo Facebook, Endler detalhou o que é IoT e suas aplicações. Apresentou exemplos de sistemas de IoT em larga escala e abordou a questão da mobilidade. O professor também descreveu em linhas gerais o ContextNet, o middleware desenvolvido integralmente no LAC (Laboratory of Advanced Colaboration) da PUC-Rio há oito anos. “Ele é escalável, tem um protocolo de comunicação confiável e leve, permite estar conectado com até 1000 IoT simultaneamente, e está disponível para uso em pesquisa ou de ensino também”, disse o professor, sobre as vantagens do ContextNet.
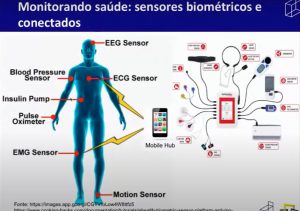
Dentre as suas áreas de aplicação, cidades inteligentes, IoT na indústria, healthcare (saúde) e monitoramento ambiental, a tecnologia pode se tornar uma ferramenta de combate ao novo coronavírus, se usada para monitorar os pacientes. Endler mostrou como funciona um componente de software para um sistema de monitoramento de pacientes com sintomas leves da Covid-19, desenvolvido no semestre passado. “Observamos que os profissionais da saúde, com tantos pacientes, têm dificuldade de perceber rapidamente a piora do estado de saúde de um paciente. E em algumas doenças infecciosas, como na Covid-19, essa piora pode ser muito rápida. Então a ideia é ter o hardware como um wearable, — que você coloca ou no dedo ou na orelha — e coleta a frequência cardíaca, a saturação de oxigênio e a temperatura. Em seguida, envia isso para o sistema de monitoramento e de alarme que vai então mandar os alarmes para os enfermeiros e médicos”, explicou o professor.
LEIA TAMBÉM:
Endler: ‘No futuro, as coisas vão se interconectar automaticamente’
Capes apoia projeto de professor do DI sobre combate à Covid-19
Jogo criado por alunos do DI e do DAD brilham na cena internacional de games
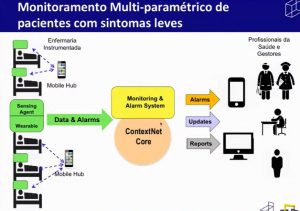
Endler apresentou a interface mobile do sistema, que mostra inclusive um gráfico com a evolução dos sintomas ao longo do tempo. “Ainda não está implantado, mas a parte de software está praticamente toda pronta”, afirmou. Além do , também é necessário um kit de sensores. “É ergonômico, leve, pequeno. E o envio de dados é ajustável. Tem a vantagem da economia da bateria. E esse kit seria de baixo custo, entre R$ 100 e R$ 400, muito abaixo do valor dos equipamentos que se usa em uma UTI”, apontou.
A live com o professor Endler está disponível no nosso canal do YouTube. Se inscreva e não perca os próximos seminários.

 Professor Marcos Kalinowski vai falar de lições a partir de experiências internacionais
Professor Marcos Kalinowski vai falar de lições a partir de experiências internacionais

 Selecionado como best paper na CMLS 2020, trabalho traz uma proposta de solução para problema relevante da bioinformática
Selecionado como best paper na CMLS 2020, trabalho traz uma proposta de solução para problema relevante da bioinformática